深入解析ClickHouse MergeTree引擎 索引结构与数据存储机制
ClickHouse作为一款高性能的列式数据库管理系统,其核心表引擎MergeTree的设计对查询性能和数据管理效率起到了决定性作用。MergeTree引擎通过独特的索引与数据存储方式,实现了海量数据的高效查询和写入,特别适合时序数据和日志分析场景。
一、MergeTree数据存储方式
MergeTree采用列式存储结构,每个数据列都独立存储在磁盘文件中,并包含对应的元数据文件。这种设计带来了几个关键优势:
- 高效压缩:相同数据类型的值连续存储,压缩率显著提高
- 查询优化:只需读取查询涉及的列,大幅减少I/O操作
- 向量化执行:支持SIMD指令,提升CPU缓存利用率
数据在磁盘上按数据分区组织,每个分区对应一个独立的目录。数据按照分区键(PARTITION BY)的值进行划分,不同分区的数据物理分离。这种分区机制使得数据删除和TTL(生存时间)管理更加高效。
二、一级索引(主键索引)
一级索引是MergeTree的核心索引机制,通过PRIMARY KEY定义,但需要注意:
- 非唯一索引:ClickHouse的主键不保证唯一性,仅用于数据排序和快速定位
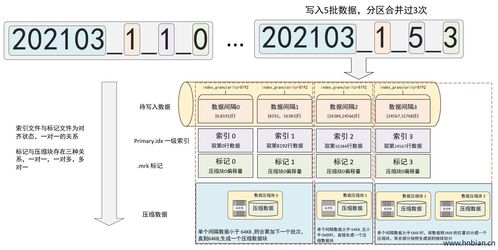
- 排序键:数据在磁盘上按主键顺序物理存储,形成稀疏索引结构
- 索引粒度:默认每8192行(通过
index_granularity参数配置)生成一个索引条目
工作机制:
- 查询时,先通过一级索引定位到可能包含目标数据的数据块(granule)
- 然后在这些数据块内进行扫描或使用其他过滤条件
- 由于数据有序存储,范围查询效率极高
三、二级索引(跳数索引)
二级索引在ClickHouse中称为跳数索引(Data Skipping Index),是MergeTree引擎的重要补充:
1. 索引类型:
- minmax:存储数据块的最小值和最大值,适合范围过滤
- set:存储数据块中所有不重复值,适合等值查询
- ngrambfv1:支持字符串的模糊匹配
- tokenbfv1:将字符串分词后建立布隆过滤器
- bloom_filter:通用的布隆过滤器实现
2. 工作原理:
- 在数据块级别创建辅助索引结构
- 查询时先检查二级索引,跳过不满足条件的数据块
- 减少不必要的数据读取,尤其对高基数列效果显著
3. 创建语法:`sql
INDEX idxcolumn columnname TYPE minmax GRANULARITY 4`
四、数据处理和存储支持服务
MergeTree引擎家族提供了一系列增强功能的数据处理机制:
1. 数据合并(Merge):
- 后台自动合并小的数据片段(parts)
- 保持数据有序性和分区结构
- 通过optimize table命令可手动触发合并
2. 数据副本(Replication):
- ReplicatedMergeTree引擎支持多副本
- 基于ZooKeeper实现副本同步和故障转移
- 提供数据高可用和负载均衡能力
3. 数据TTL(生存时间):
- 支持表级和列级TTL配置
- 自动删除过期数据或移动到其他存储介质
- 支持分层存储(热数据SSD,冷数据HDD)
4. 投影(Projection):
- 预计算并存储特定查询模式的结果
- 自动维护与基表数据的一致性
- 显著提升聚合查询性能
5. 数据压缩与编码:
- 支持多种压缩算法(LZ4、ZSTD等)
- 列级编码优化(Delta、DoubleDelta、Gorilla等)
- 自适应压缩策略根据数据类型选择最优方案
五、最佳实践建议
- 主键设计:选择常用的过滤条件作为主键,控制主键列数量(通常2-4列)
- 分区策略:避免创建过多小分区,一般按时间分区(如按天/月)
- 索引优化:高基数列考虑使用二级索引,定期分析索引效果
- 存储优化:根据访问模式配置合适的压缩算法和编码方式
- 监控维护:定期监控parts数量和合并状态,避免过多小文件
六、性能对比示例
以包含1亿行数据的表为例:
- 无索引全表扫描:耗时约30秒
- 使用一级索引的范围查询:耗时约0.5秒
- 结合二级索引的等值查询:耗时约0.1秒
通过合理设计MergeTree表的索引结构和存储参数,ClickHouse能够在大数据场景下实现亚秒级的查询响应,成为实时分析场景的强力工具。
如若转载,请注明出处:http://www.xnjindouyun.com/product/66.html
更新时间:2026-04-18 17:16:46